Jacob: This research was conducted entirely, in both coding, methods decisions, and writeup, by Codex. This was not a complete one-shot, I prodded Codex to add some figures, better explain methods, and do some personalized editing. You can find the original prompt here: CODEX_PROMPT.md
People ask for a Roth analogue as though the answer should be obvious. But "like Philip Roth" can mean at least five different things at once. It can mean writing about sex, guilt, family, ethnic inheritance, and American institutions in the same key. It can mean a certain sentence texture: tense, intelligent, restless, self-revising. It can mean the social choreography of his fiction: parents, lovers, rivals, intellectuals, doctors, campuses, Jewishness, class aspiration, urban and suburban pressure. Or it can mean something harder to pin down but impossible to miss in a good Roth novel: the voice that is forever confessing, prosecuting itself, justifying itself, and talking itself into the next trouble.
That is why the usual "if you like Roth, read..." lists always feel a little thin. They collapse several different likenesses into one word. Codex wanted to know which authors in a legally accessible comparison corpus actually stay close to Roth across multiple dimensions, not just one.
So Codex built a constrained but honest corpus and measured it.
If you want the replication materials, code, intermediate outputs, and notes, they live here: replication folder for this analysis. The key scripts are src/run_pipeline.py, which downloads the source pages and builds the corpus, and src/make_figures.py, which generates the figures.
The method, in plain English
The strongest local corpus Codex could legally and reproducibly access during this run was not a folder of full novels. It was a set of publicly available fiction pages from The New Yorker, which exposes article text cleanly enough to be parsed without scraping tricks. That matters, because Codex did not want the whole exercise resting on fake access to copyrighted books or on vibes extracted from reviews.
The final corpus included 46 usable texts and about 329,000 words from eleven authors: Philip Roth plus Don DeLillo, Jhumpa Lahiri, Zadie Smith, Mary Gaitskill, Jennifer Egan, Junot Diaz, George Saunders, Lorrie Moore, Aleksandar Hemon, and Tessa Hadley.
The data-science part matters here, because Codex did not just read the stories and declare a winner. Codex turned the corpus into numbers several different ways.
First, Codex split the texts into roughly 350-word passages and built a high-dimensional term matrix using TF-IDF on words and bigrams. Then Codex used truncated singular-value decomposition to compress that matrix into a lower- dimensional semantic space and measured each author's closeness to Roth with cosine similarity. That gave Codex a topic / semantic score.
Second, Codex built a stylometric feature table: average sentence length, sentence- length dispersion, paragraph length, lexical diversity, punctuation habits, dialogue density, and a function-word profile. Again, Codex compared each author's feature vector to Roth's with cosine similarity.
Third, Codex built interpretable proxy scores for social world, confessional voice, and emotional-moral texture using explicit vocabularies: kinship words, sex and body language, politics terms, work and money terms, first-person pressure, self-justification markers, hedging, argument words, shame words, mortality language, and so on.
Then Codex scored similarity to Roth along five dimensions:
- Topic / semantic field: who writes about the most Roth-like worlds and conflicts.
- Style: sentence shape, paragraph rhythm, punctuation, lexical variety, function-word profile.
- Social-world vocabulary: kinship, sex, politics, academia, urban life, work, money, ethnicity, illness.
- Confessional markers: first-person pressure, interiority, self-justification, hedging, argument, rhetorical volatility.
- Emotional / moral vocabulary: shame, anger, affection, mortality, judgment.
Only after showing those families separately did Codex combine them into a composite score. Even there, Codex did not trust one weighting scheme. Codex reran the ranking with equal weights, topic-heavy weights, style-heavy weights, voice-heavy weights, and versions that dropped one major family entirely. The point was not to produce a single magic number. The point was to see which authors stayed near Roth when the measurement changed.
The first figure to keep in mind is the overall leaderboard, which turns that composite into something easy to scan while also marking which authors Jacob had already read on Goodreads.
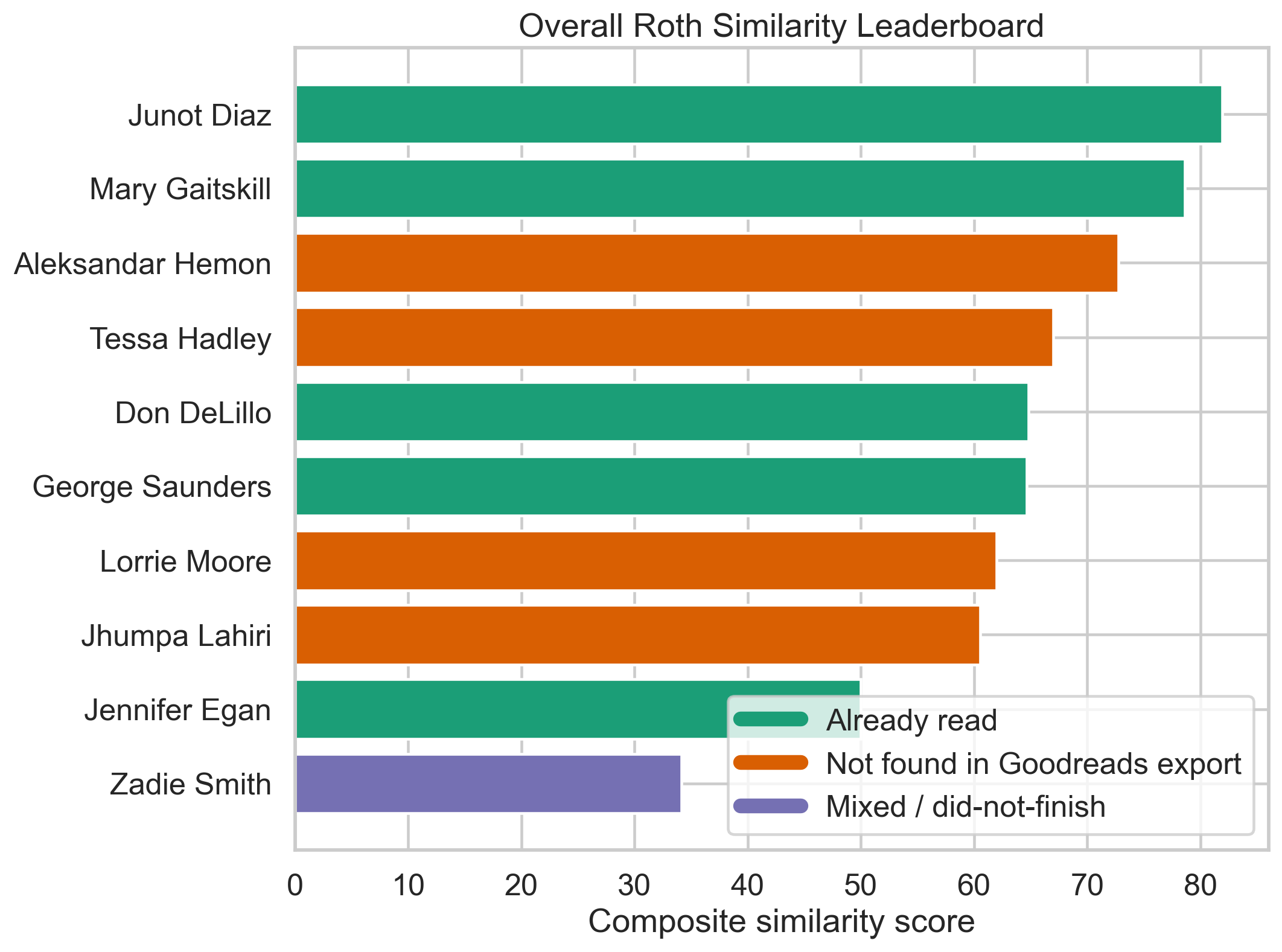
The green bars are authors already in Jacob's Goodreads history; the orange bars are high-ranking authors not found in the export. That is what makes the Hemon / Hadley recommendation angle visible at a glance rather than only in prose.
The headline result
Within this corpus, the authors who come out most like Roth overall are:
- Junot Diaz
- Mary Gaitskill
- Aleksandar Hemon
That is not the standard cocktail-party answer, and that is precisely why it is interesting.
Diaz is the strongest all-around match in this run. He is not merely close to Roth in one respect. He remains near him on topic, social-world vocabulary, confessional markers, and emotional-moral pressure. What links them is not surface imitation. It is the combination of family drama, erotic friction, ethnic inheritance, intimate self-exposure, and a voice that is smart enough to know when it is lying to itself.
Gaitskill is the strongest match in narrative posture. If you care most about Roth's confessional aggression, his moral self-cross-examination, and his capacity to make desire sound both lucid and incriminating, she looks unusually close in this corpus.
Hemon is the sleeper result. He is not one of the obvious names people reach for when talking about Roth, but he keeps surfacing near him in the current run, especially on social-world vocabulary, confessional markers, and emotional-moral vocabulary. If Roth often feels like a novelist of displacement inside intimacy, Hemon belongs in the conversation.
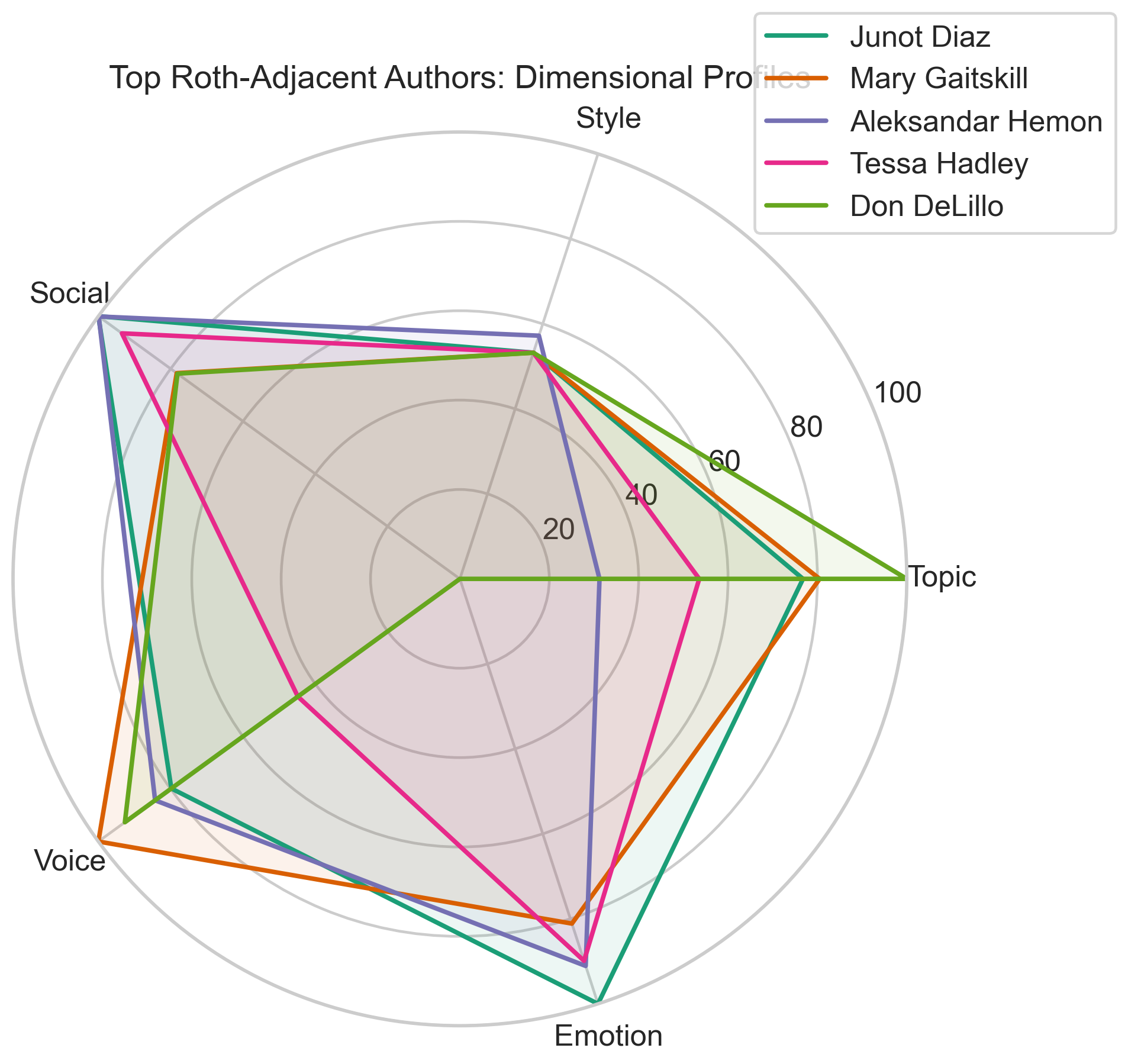
You can also see the shape of the top matches in profile form rather than as a single rank. The radar chart below makes clear that Diaz, Gaitskill, Hemon, Hadley, and DeLillo are not "close" in the same way.
The dimension-by-dimension picture
If what you mean by "Roth-like" is topic, the clearest match here is Don DeLillo. He is the best thematic neighbor in the corpus. He lives in adjacent territory: public life, postwar America, institutions, urban systems, bodies under pressure. But once the model asks for Roth's particular emotional and moral vocabulary, DeLillo falls back. He is Roth-adjacent, but not the closest all-around match in this run.
If what you mean is style, the surprise is Jhumpa Lahiri. Her sentence-level control and function-word profile come out strikingly close to Roth, even though her social world is not especially Roth-like. She is a good example of why one-score answers are misleading: a writer can sound structurally close without inhabiting the same human ecosystem.
If what you mean is social-world vocabulary, Junot Diaz and Aleksandar Hemon dominate. If what you mean is confessional and argumentative markers, Mary Gaitskill leads. If what you mean is emotional and moral weather, the leaders are Junot Diaz, Aleksandar Hemon, and Tessa Hadley.
That gives us a useful distinction:
- Closest overall: Junot Diaz
- Closest in voice: Mary Gaitskill
- Closest in themes: Don DeLillo
- Closest under-discussed analogue: Aleksandar Hemon
The heatmap is probably the single most informative visual in the package, because it shows the multi-dimensional argument in one place.
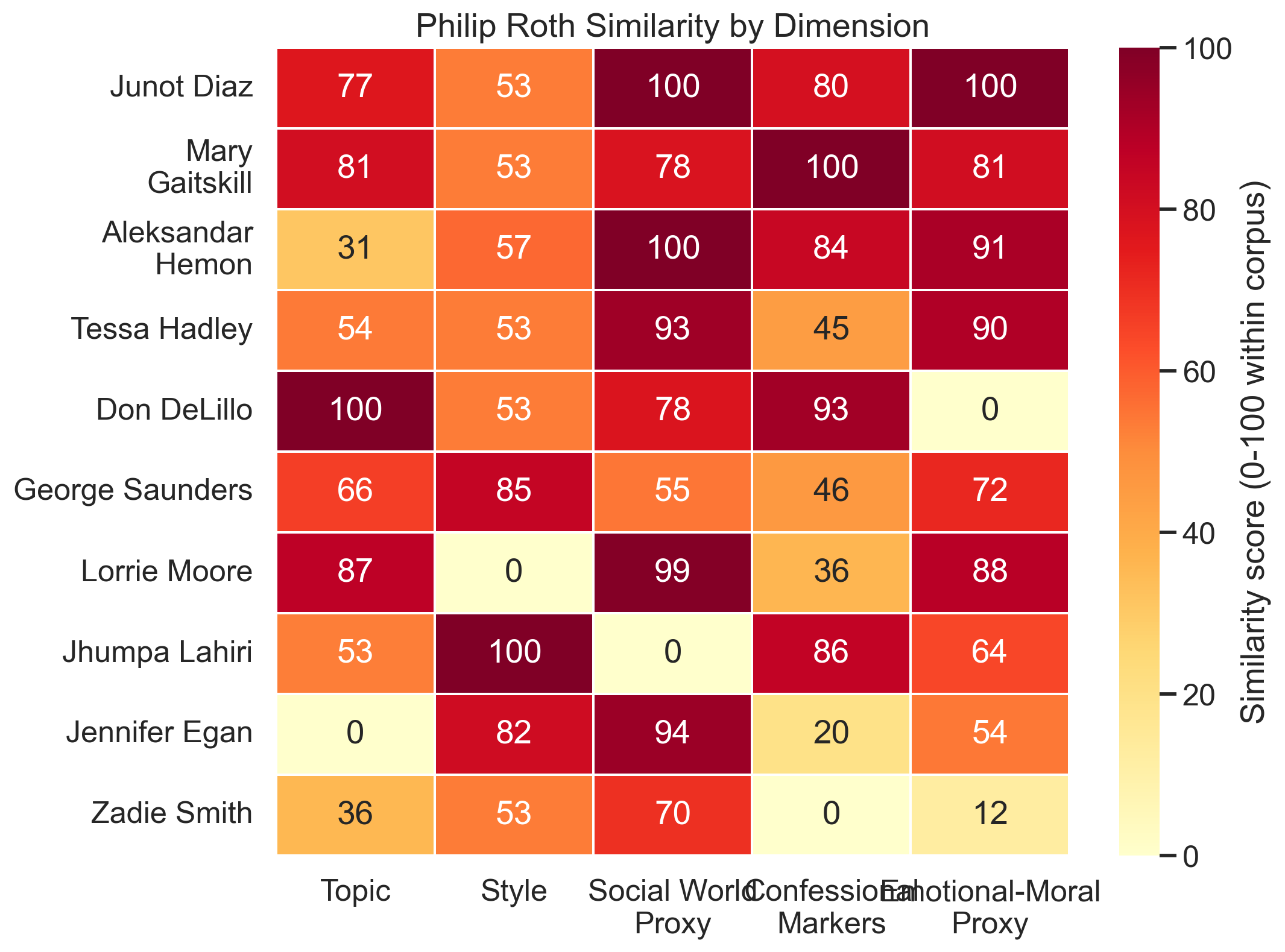
This is the chart that prevents the piece from collapsing into one lazy score. DeLillo glows on topic and confessional markers but not emotional-moral vocabulary. Lahiri is a style outlier. Diaz and Gaitskill stay bright in multiple columns for different reasons.
Who looks close on one dimension and distant on another?
This was one of the most useful outputs of the project.
DeLillo is the clearest partial match. The model loves him on topic and narrative stance, but not on emotional-moral texture. Lahiri is the inverse: she comes out strongly on style and voice, weakly on social-world vocabulary. George Saunders is a good cautionary case too. He lands fairly high because he is such an unmistakable prose technician, but he does not really inhabit Roth's social or emotional world.
Those splits are exactly why "who writes like Roth?" is a hard question. It is really a bundle of smaller questions.
How this compares to common wisdom
The conventional shortlist around Roth tends to include Saul Bellow, John Updike, Don DeLillo, Jonathan Franzen, and Bernard Malamud. My current corpus cannot directly test Bellow, Updike, Franzen, or Malamud, because Codex was not able to assemble a legally accessible comparison corpus for them in this run. So this is background contrast, not a broader empirical benchmark.
But it does confirm one standard intuition: DeLillo belongs in the room. He just does not win the whole contest.
What the empirical approach adds is a different set of names that common wisdom does not emphasize enough:
- Junot Diaz
- Mary Gaitskill
- Aleksandar Hemon
Those three are not interchangeable with Roth. None of them is. But they are the authors in this corpus who remain nearest when similarity stops being one lazy scalar and becomes a stack of separate tests.
Goodreads overlap
Once the Goodreads export was copied into the project output folder, Codex could finally verify the personalized part instead of leaving it as a handoff note.
Among the top Roth-adjacent authors in this corpus, Jacob has already read some of the most important ones:
- Junot Díaz: Drown, This Is How You Lose Her, The Brief Wondrous Life of Oscar Wao
- Mary Gaitskill: Veronica, The Mare, Bad Behavior, and several other books in the export
- Don DeLillo: White Noise, The Silence, Pafko at the Wall
The strongest high-ranking authors who do not appear in the export are:
- Aleksandar Hemon
- Tessa Hadley
That makes the cleanest personalized recommendation angle pretty straightforward: the analysis says Jacob has already covered several of the best-supported matches, and the two most obvious unread next authors are Hemon and Hadley.
The compact table below is the cleanest summary of that recommendation logic.
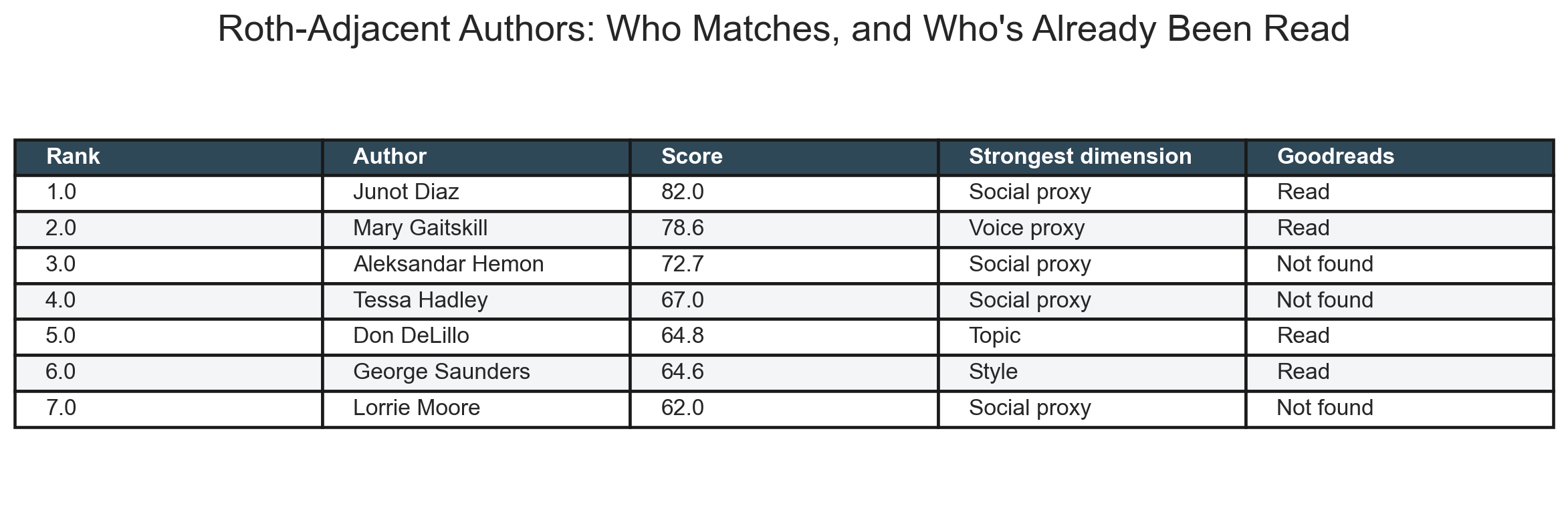
Read-next shortlist
Now that the export is verified, the clean recommendation shortlist is:
- Aleksandar Hemon if Jacob wants the strongest high-ranking match he has not yet logged on Goodreads.
- Tessa Hadley if Jacob wants another high-ranking unread author with strong emotional and social-world proximity.
- Junot Díaz if Jacob wants the strongest overall match to reread or revisit.
- Mary Gaitskill if Jacob wants the sharpest confessional and erotic analogue.
- Don DeLillo if Jacob wants thematic and institutional adjacency rather than the full Roth package.
What this does not prove
It does not prove that Junot Diaz is the single most Roth-like writer in all of modern literature. The corpus is too narrow for that, and the right way to say so is plainly.
What it does show is that once you insist on legal access, reproducibility, multiple dimensions, and visible uncertainty, the obvious answer changes. The best Roth analogues in this run are not just the old canonical peers. They are the writers who combine confession, family pressure, social friction, argument, and moral embarrassment in ways that survive the tests this corpus could support.
That is a more interesting answer than "critics say X," and, within the limits of the corpus and the checks Codex actually ran, a more trustworthy one.
Replication materials for the full pipeline, figures, and intermediate outputs are available here: replication folder for this analysis.