Suppose I want to know whether some characteristic of a place $X_p$ affects an individual outcome $Y_i$. There are two challenges to inference.
First, people sort into places. If the kind of person who moves to a high-$X$ place would have had different outcomes regardless, then comparing across places confounds $X$ with individual selection. This is the standard worry in observational causal inference: place assignment is endogenous.
Second, places are bundles. A neighborhood with high $X$ also has particular schools, crime rates, pollution levels, social networks, and dozens of other attributes that co-vary with $X$ across places. Even if I solve the selection problem perfectly, I still cannot tell whether it is $X$ or something bundled with $X$ that drives the outcome.
The two paths
Call the first problem Path 1 (individual selection into place) and the second Path 2 (overlapping place characteristics). In DAG terms:
Path 1: $X_p \leftarrow P_i \leftarrow \mathbf{W}_i \rightarrow Y_i$
Individuals with pre-treatment characteristics $\mathbf{W}_i$ sort into places non-randomly, and $X_p$ inherits a spurious correlation with $Y_i$ through the sorting process.
Path 2: $X_p \leftarrow P_i \rightarrow \mathbf{Z}_p \rightarrow Y_i$
Place jointly determines $X_p$ and every other place characteristic $\mathbf{Z}_p$. Variation in $X$ across places is bundled with variation in $\mathbf{Z}$.

Identifying the overall effect of place only requires closing Path 1. Identifying the effect of a characteristics of place technically is possible if place is endogenous, requiring that either the characteristic of interest is the only thing that can affect the outcome or that it is uncorrelated with all other potential overlapping characteristics that influence the outcome. More commonly, identifying the characteristic effect requires closing both paths.
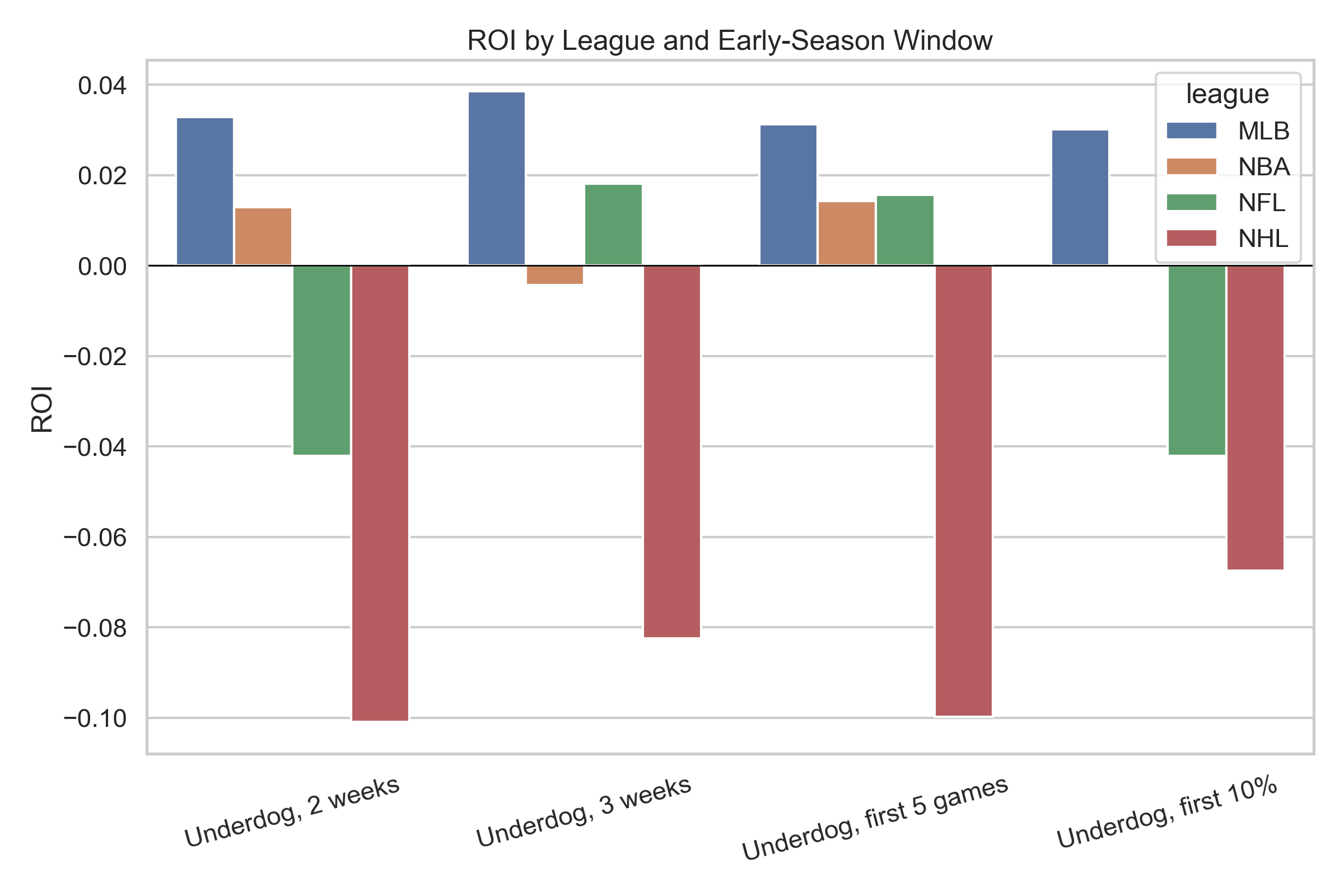
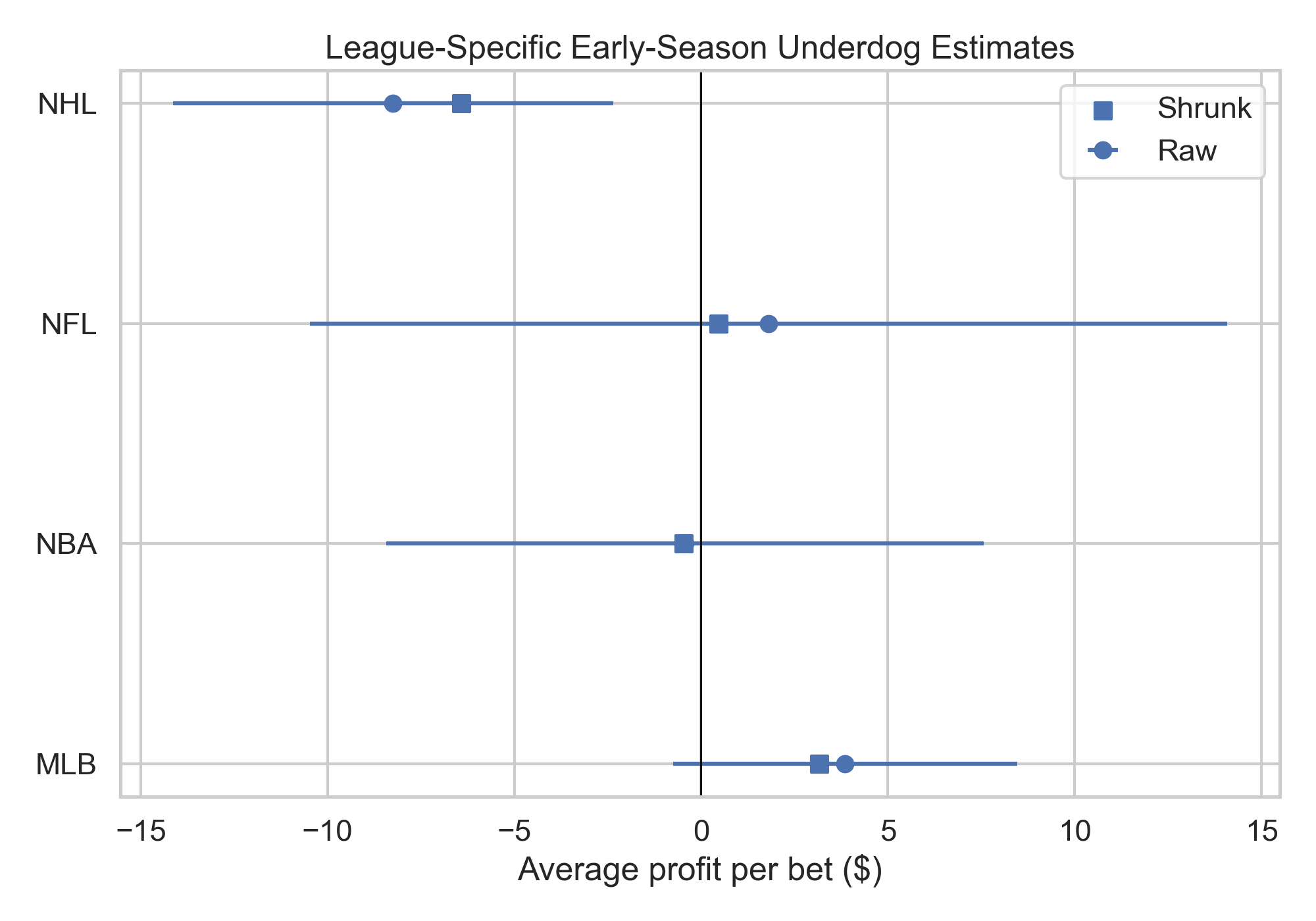
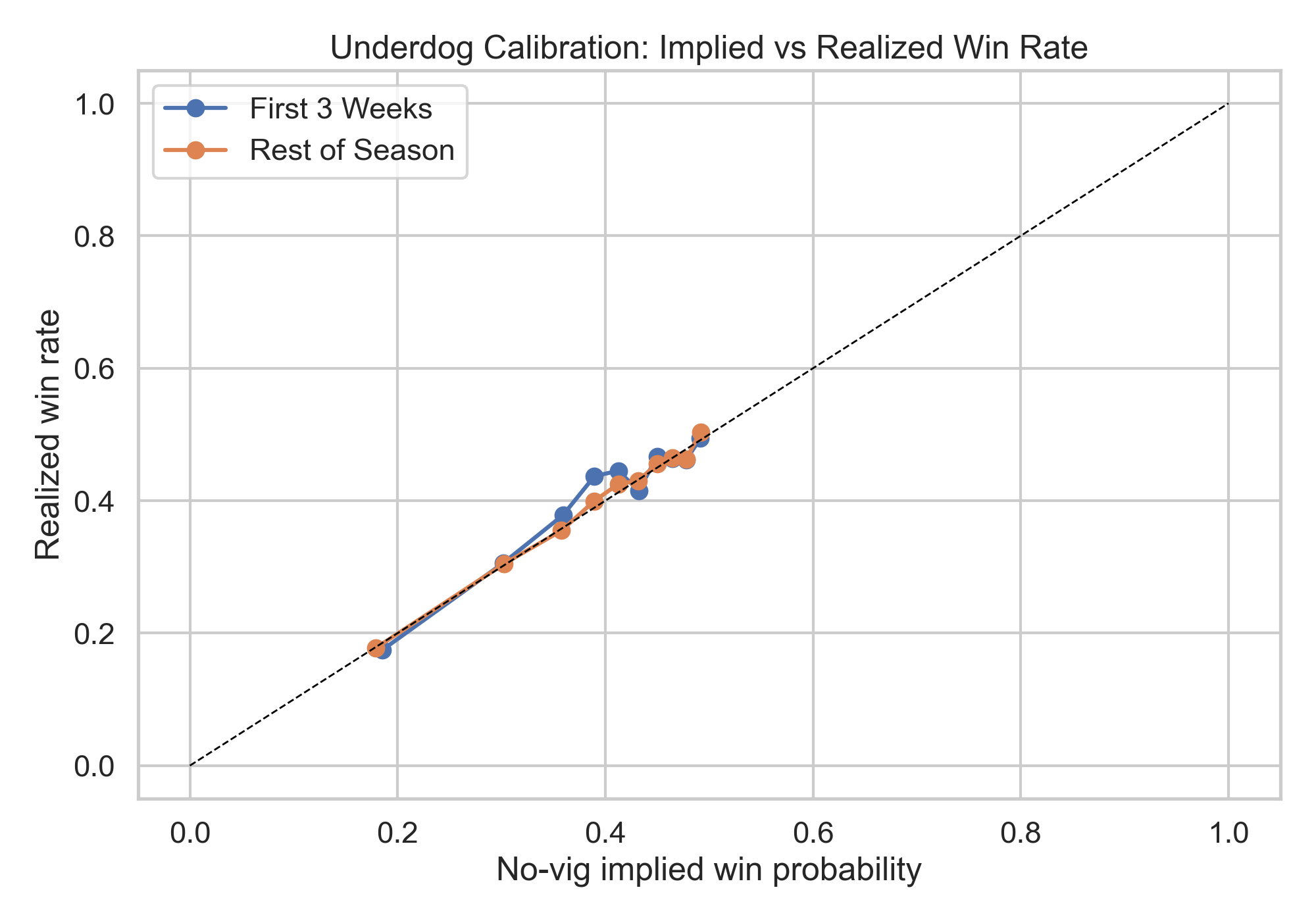
The typical case is that both paths are open, which makes causal claims about place characteristics doubly hard. Here is how four common identification strategies fare.
Randomized relocation
The Moving to Opportunity experiment randomly assigned housing vouchers, allowing some families to move from high-poverty to lower-poverty neighborhoods. Randomization closes Path 1 completely — no functional form assumptions, no conditional independence, no parallel trends.
But the experiment randomizes access to a bundle of neighborhood characteristics, not to $X$ specifically. Families who used their voucher moved to places that differed from their origin neighborhoods in poverty, school quality, crime, pollution, and much else, all at once. The estimated treatment effect captures the composite:
Path 2 remains open. The experiment tells us whether relocation influenced outcomes, but not what characteristics of place made that influence.

Childhood mover design
The childhood mover design compares children who move between the same origin and destination at different ages. Those who move younger spend more time in the destination relative to the origin and thus may be more influenced by the destination than children who moved later in childhood. The identifying assumption here is that age at move is as-if randomly assigned. This assumption identifies $\mu_p$, the causal exposure effect of place $p$ per year of childhood.
Path 1 is closed in this scenario, but $\hat{\mu}_p$ captures just the overall effect of place, as it is estimated from regressing mover outcomes on the outcomes of their never mover peers and seeing whether convergence is higher for those who move earlier. Researchers could regress $\hat{\mu}_p$ on $X_p$ to try isolate the role of a specific characteristic, but that regression is subject to Path 2 confounding: $\text{Cov}(X_p, \mathbf{Z}_p) \neq 0$ across places.

Difference-in-differences
Difference-in-differences exploits within-place changes in $X$ over time, using individual or place fixed effects to absorb time-invariant confounders. Fixed effects account for time-invariant characteristics that led people to live where they do (Path 1) and accounts for overlapping characteristics of place that do not change across time (Path 2). But confounding remains from co-trending characteristics.
Thus, DiD partially addresses both paths but only partially. The parallel trends assumption has to work double, covering both selection on trends in potential outcomes and the possibility that other place characteristics co-move with $X$.

Spatial regression discontinuity
A spatial RD exploits a boundary where $X$ changes discontinuously. Individuals just on either side of the boundary are comparable so long as the continuity assumption holds, and if so Path 1 is closed (but we should perhaps be skeptical of meaningful boundaries having only meaningless sorting around them), and if $X$ jumps at the boundary but other place characteristics $\mathbf{Z}_p$ do not, then the local variation in $X$ is free of Path 2 confounding.

Path 2 as a construct validity problem
In many settings $X_p$ does not vary independently of $\mathbf{Z}_p$ even in principle, so the effect of a specific place characteristic may not be point-identified without functional form assumptions. In practice, Path 2 is a construct validity problem. A design gives you credible variation in something, and whether that something corresponds to the theoretical construct you care about is a separate claim — like a survey experiment that aims to prime one emotion but may prime others alongside it. When clean identification is not available, researchers fall back to inference to the best explanation, arguing for the characteristic-specific effect through abductive reasoning.