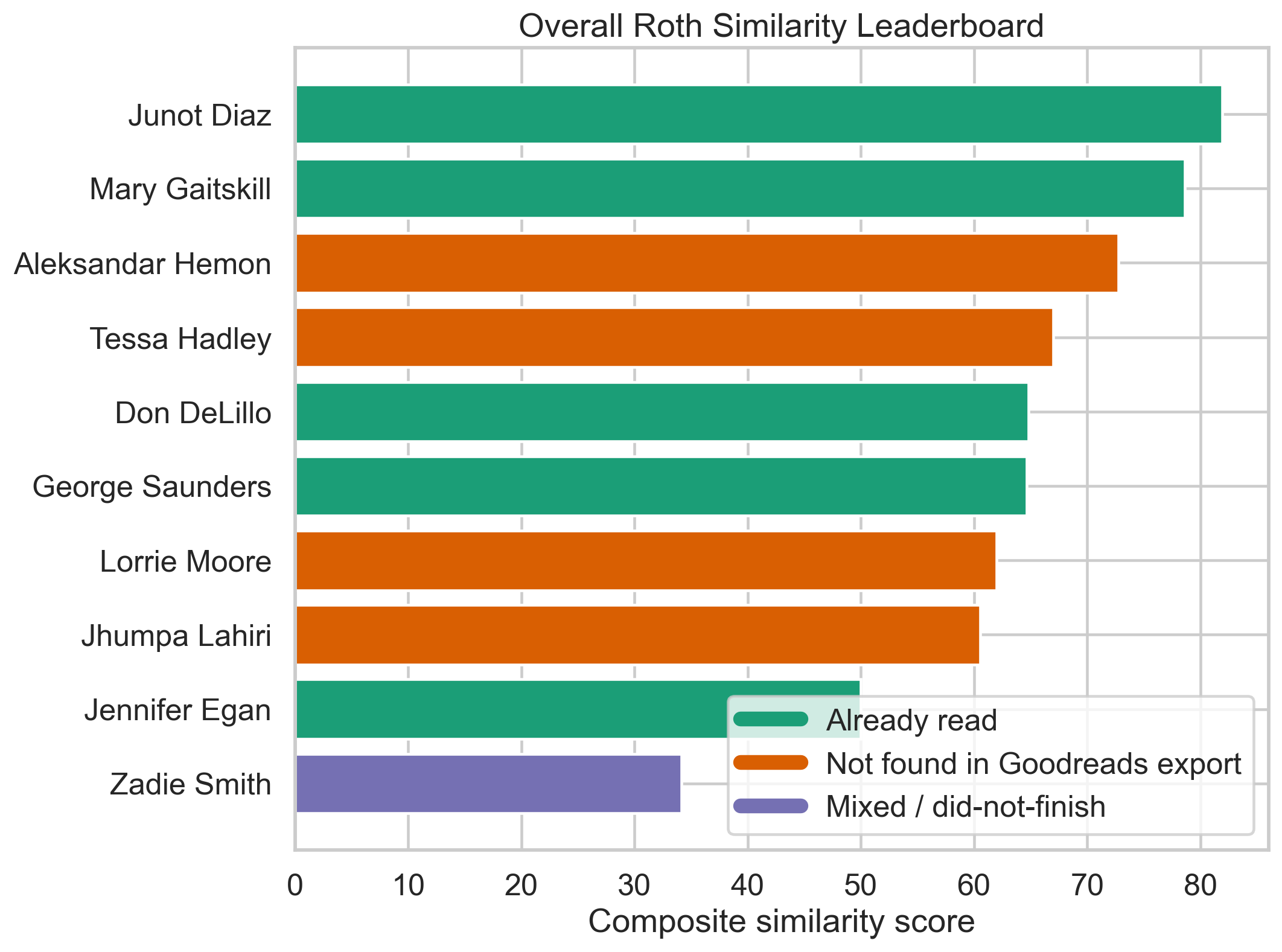
Jacob: This research was conducted entirely, in both coding, methods decisions, and writeup, by Codex. This was not a complete one-shot, I prodded Codex to add figures, better explain the methods and clustering statistics, and tighten the claims after adversarial review. You can find the original prompt here: CODEX_PROMPT.md
Belmont's public coyote map is the kind of thing that dares you to overinterpret it. The points are visibly uneven. They look denser in some parts of town than others, especially toward Belmont's greener western side. If you were moving quickly, you could look at that map and say: there, that's where the coyotes are.
That is exactly the temptation this post is trying to resist.
Opportunistic wildlife sightings are not telemetry. They are not a census. They are not a uniform sample of animal locations. They are a human reporting process laid on top of an animal process. A cluster of reports can mean more coyotes, more people noticing coyotes, more people willing to file reports, repeated reports from the same vantage point, or some combination of all of those.
Belmont's data are unusually useful because the public map exposes enough structure to let us test some of those possibilities directly. We can recover the point geometry, report date, report time, and reporting address. We cannot identify reporters by name, and we cannot read narrative notes. So this is not a detective story about proving a literal super-caller. It is a spatial-analysis story about what kinds of clustering survive once we confront duplicate locations, repeated addresses, temporal concentration, and weak ecological controls.
My bottom line is careful but not trivial: Belmont's public coyote reports are clearly non-uniform in space, but the strongest interpretation supported here is non-uniform report concentration, not a clean map of coyote behavior. Repeated origins matter a lot. A simple habitat story is not well supported by the first-pass contextual tests. The right conclusion is a mixture, with reporting concentration carrying more of the evidentiary weight than habitat concentration in this version of the analysis.
The data we actually have
Belmont's public PeopleGIS viewer includes a Coyote Sightings layer. The town does not expose it as an easy one-click download, but the web app's own query endpoint returns a structured record set. Recovering that public payload yielded 290 reports with:
- point geometry
- reporting address
- report date
- time string
- internal record identifiers
What the public layer does not expose is just as important:
- no reporter identifier
- no narrative note text
- no explicit duplicate flag
That means the analysis can test for repeated locations and repeated addresses, but not for repeated named reporters. It also means every claim in this piece has to stay one step more modest than it otherwise might.
To put the reports in context, I joined the points to a Belmont town boundary and clipped in two official statewide context layers from MassGIS:
- protected and recreational open space
- National Wetlands Inventory wetlands
Those are useful first-pass context layers, but they are not an exposure-aware model of where people live, walk, or decide to report. That matters later.
Figure 1: the raw map already hints at the problem
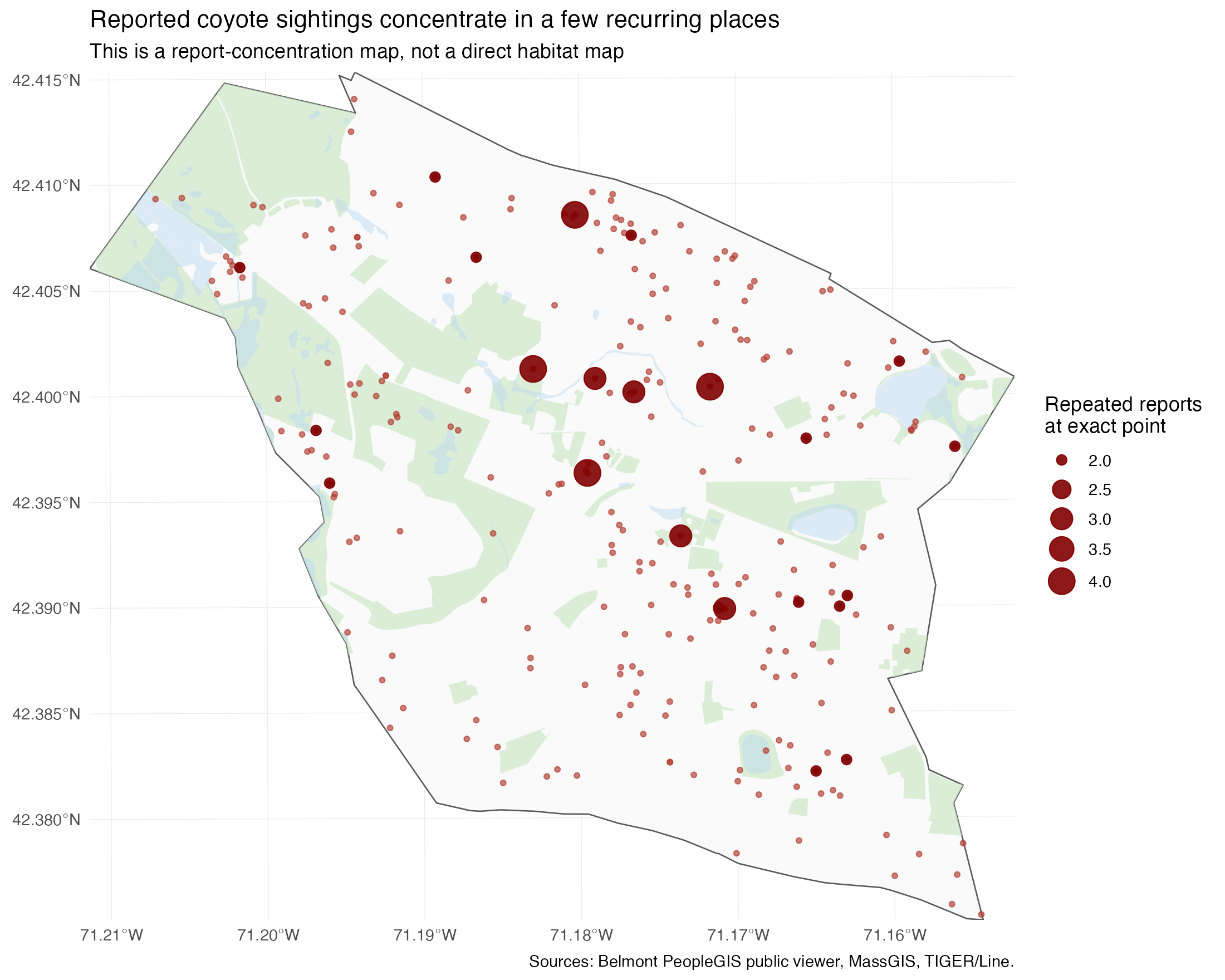
Figure 1. Raw Belmont coyote reports over Belmont boundary, open space, wetlands, and repeated exact locations. Larger dark-red symbols mark exact coordinates that appear more than once.
Figure 1 is the obvious starting point. The reports are not spread evenly across Belmont. But just as important, some places recur. The larger dark-red points show exact coordinates that appear repeatedly in the public archive. That is the first reason not to read the map as direct habitat telemetry. The same mapped place can contribute multiple reports over time.
Even visually, this is a mixed signal. There is some western-side concentration, but there are also central and south-central reports. And the repeated points are often on ordinary residential streets, not just on the edges of mapped open space. So before doing anything more sophisticated, the raw map already tells us that two stories are plausible at once:
- a spatial pattern in where coyotes are encountered
- a spatial pattern in where people repeatedly observe and report them
The statistical setup
Because the audience here is data-science-y, it is worth being explicit about what was actually estimated.
The analysis pipeline treated Belmont as a bounded observation window and ran several complementary diagnostics:
- Nearest-neighbor ratio against CSR For each scenario, I computed the mean nearest-neighbor distance among points and divided it by the expected mean nearest-neighbor distance under simulated complete spatial randomness inside Belmont. The ratio is below 1 when points are more tightly packed than the null. This is useful as a non-uniformity diagnostic, but here it is a test of report concentration under a uniform-placement null, not a clean ecological test.
- Quadrat test Belmont was partitioned into a 4x4 grid and the count pattern was tested against uniform intensity. This is a blunt but interpretable test for uneven spatial counts. Again, in this setting it is a reporting-process benchmark more than a behavioral one.
- Ripley's L I estimated Ripley's L and compared it to a Monte Carlo CSR envelope. This helps show whether the pattern is more clustered than CSR over a range of distances instead of at just one nearest-neighbor scale.
- Kernel density estimation I fit a KDE using Diggle's bandwidth rule. KDE is descriptive, not dispositive. It can summarize where reports pile up under one smoothing choice, but it is not itself a causal argument.
- Local Moran hotspot map I aggregated reports to a Belmont-clipped fishnet and ran local Moran's I. This is also descriptive and scale-sensitive. I explicitly saved a sensitivity table across 150 m, 250 m, 400 m, and 600 m grids because one hotspot map can easily look more definitive than it really is.
- raw reports - unique exact coordinates - a version with the five most repeated exact locations removed
- Duplicate and repeat-origin diagnostics This is the real center of gravity of the piece. I compared:
I also summarized repeated reporting addresses, same-address same-day repeats, same-address same-week repeats, and addresses that map to more than one coordinate.
- Ecological-context comparisons I compared unique sighting locations to random points inside Belmont using distance to open space and distance to wetlands, plus a simple logistic model on log-distance predictors. These are only first-pass diagnostics because the controls are not exposure-aware. A random point inside a wetland is not a realistic stand-in for a human reporting opportunity.
That setup matters because every conclusion below depends on what the null is. If you compare a human-origin reporting archive to uniform random points over all of Belmont, rejecting that null tells you the reports are not uniform. It does not tell you, by itself, that coyotes are choosing those exact places.
Figure 2: yes, the reports are clustered under a simple null
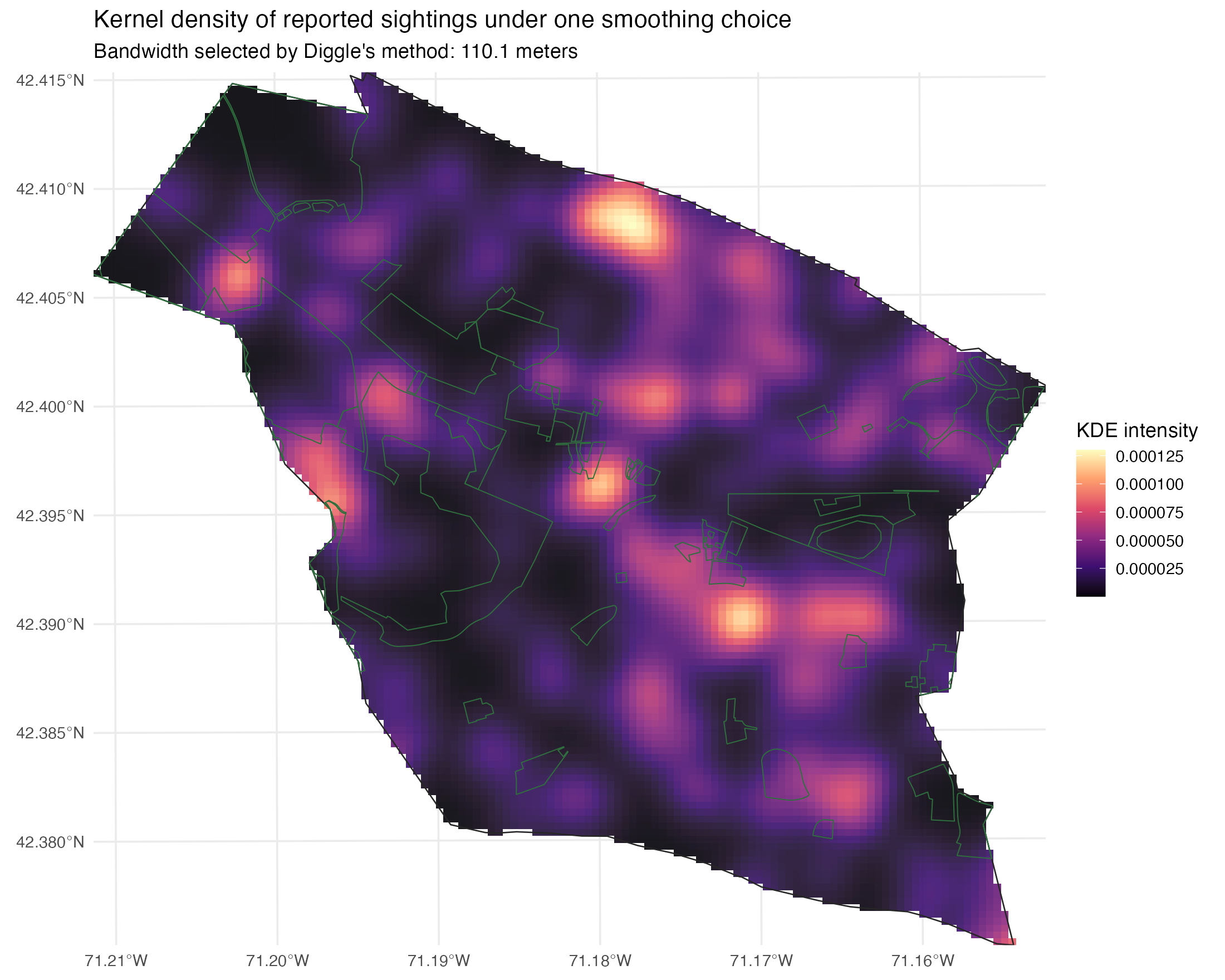
Figure 2. Kernel density surface for raw reports under one smoothing choice. This is descriptive smoothing of a reporting archive, not direct evidence of coyote habitat use.
Under a simple CSR benchmark, Belmont's reports are clearly non-uniform.
The main clustering results are:
- raw nearest-neighbor ratio: 0.697 with Monte Carlo p = 0.005
- unique-location nearest-neighbor ratio: 0.833 with Monte Carlo p = 0.005
- raw quadrat test p = 1.6e-07
- unique-location quadrat test p = 2.01e-05
- Ripley's L exceeds the CSR envelope in the tested distance range for all three scenarios saved in the output
So if the question is "are these reports spatially uniform over Belmont?", the answer is clearly no.
But that is only the first question. Figure 2 is useful because it shows where the archive looks dense under one smoothing rule. It is not useful as a shortcut to "this is where coyotes live." KDE will always make repeated and nearby reports look like a broad underlying surface, even when some of the structure comes from repeated origins.
There is a second complication too: the archive is pooled over a long time span. About 46.0% of the dated reports fall in 2011-2012 alone. So any all-years density surface is blending together different reporting eras as well as different locations.
Figure 3: repeated origins are not a side issue
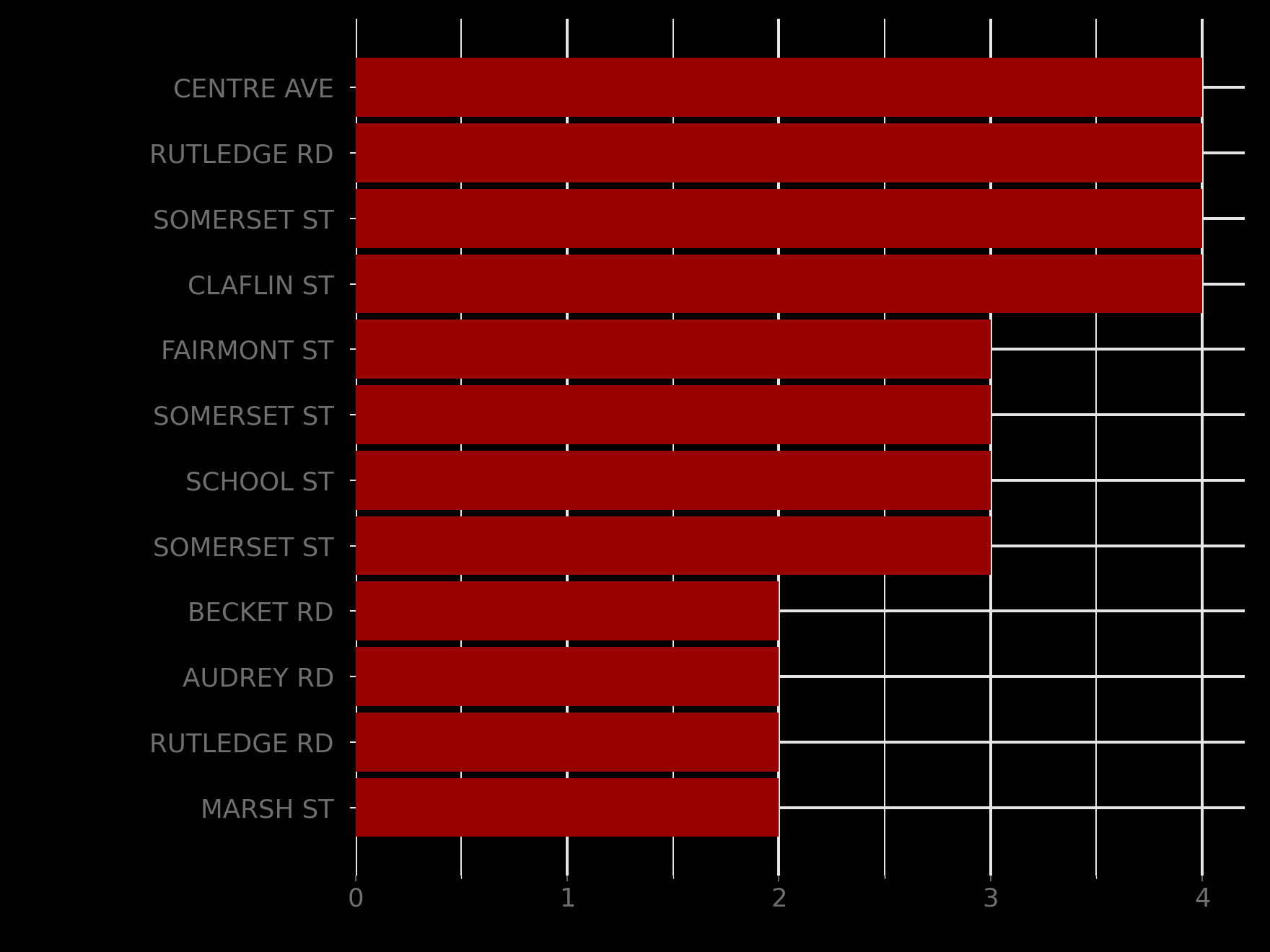
Figure 3. Top repeated report origins in the raw report set, with house numbers omitted from the labels for privacy.
If the whole map were being driven by one spectacular super-caller, the story would be easy. The public data do not let us prove that, and the evidence does not support that kind of dramatic claim anyway.
But Figure 3 shows something important and more defensible: repeated origins are common enough to materially shape the map. To avoid pointing readers at a specific household, the figure omits house numbers from the labels rather than printing the full addresses.
The duplicate and repeat-origin diagnostics show:
- 22.8% of all reports fall on exact coordinates that repeat
- 27.0% of nonblank-address reports come from addresses that repeat
- 25 reporting addresses appear at least twice
- 6 addresses recur in more than one mapped coordinate
- 5 same-address same-day repeat events appear in the public layer
- 6 same-address same-week repeat events appear in the public layer
That is not evidence of fraud, fakery, or one obsessive resident running the entire map. It is evidence that repeated report origins are structurally important. Once roughly a quarter of reports come from repeated exact points or repeated addresses, any naive heatmap interpretation becomes much too strong.
Figure 4: clustering survives deduplication, but it weakens
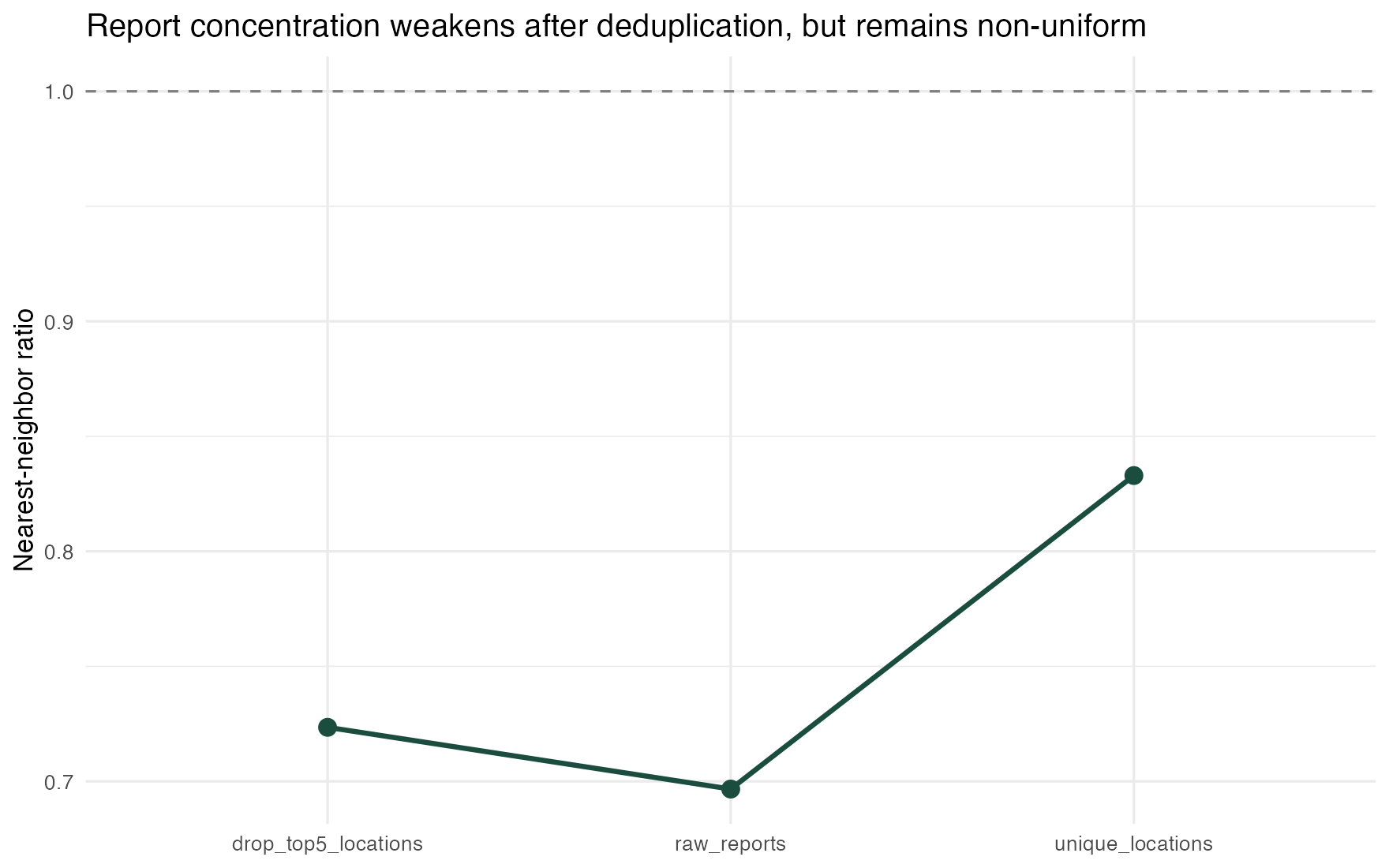
Figure 4. Robustness check using the nearest-neighbor ratio. Moving from raw reports to unique exact locations weakens clustering, but does not eliminate non-uniformity.
Figure 4 is the most important figure in the post.
The raw archive contains 290 reports, but only 251 unique exact locations. When repeated exact points are collapsed, the nearest-neighbor ratio moves from 0.697 to 0.833. That is still below 1. The pattern is still non-uniform. But the clustering gets less dramatic once repeated coordinates stop counting as independent observations.
That is the strongest clean result in the package:
- there really is spatial concentration in the reporting archive
- some of that concentration survives deduplication
- but the raw archive makes the pattern look sharper than it is
The top-five-location removal check points in the same general direction, though less cleanly across every metric. That is why the post now treats the robustness result as "clustering weakens" rather than "the truth emerges once duplicates are removed." Even after deduplication, the residual pattern could still reflect broader reporting opportunity rather than coyote behavior per se.
Figure 5: hotspot geography is descriptive and scale-sensitive
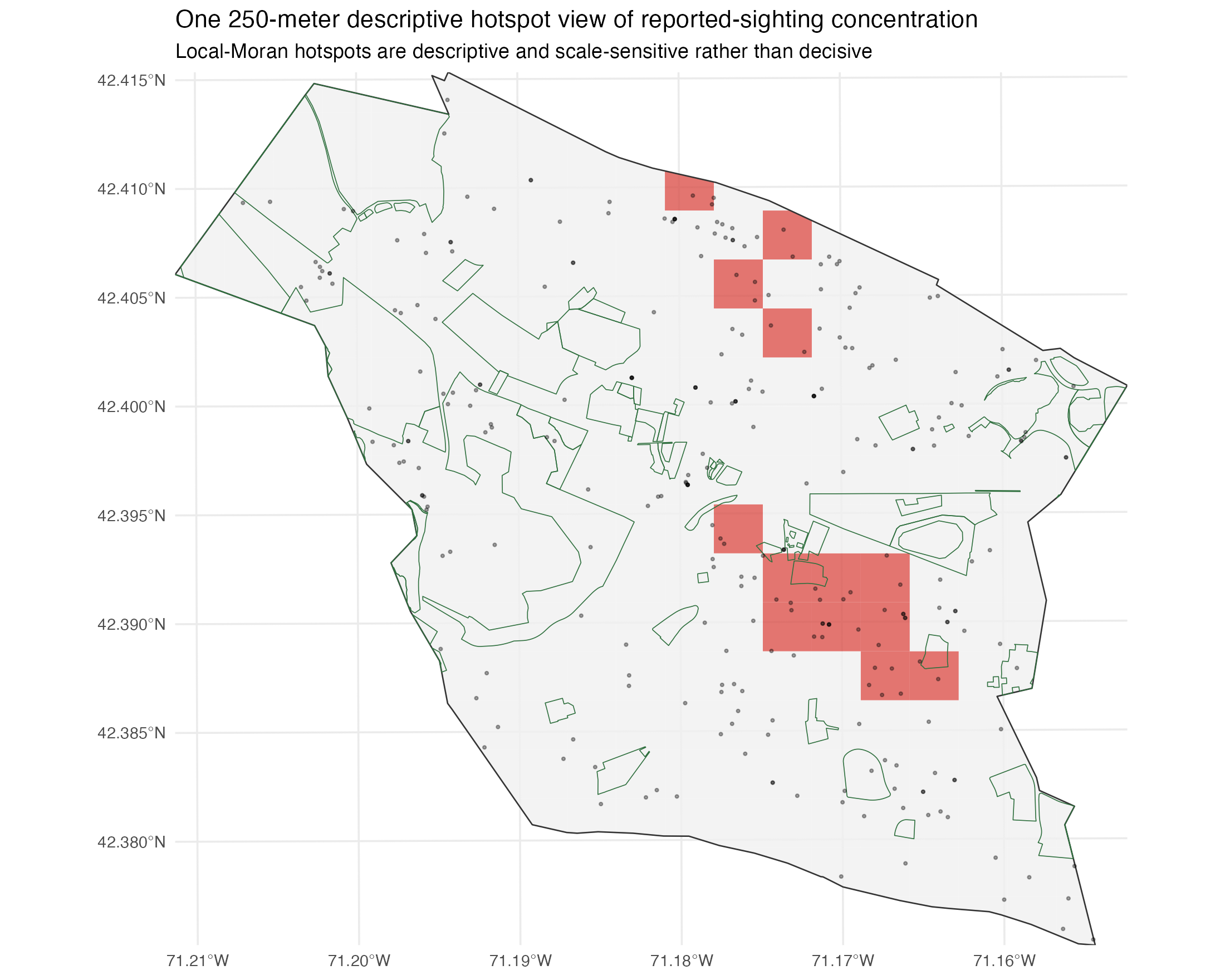
Figure 5. One 250-meter hotspot view of reported-sighting concentration. This map is descriptive; the hotspot footprint changes materially with grid size.
Figure 5 is useful, but only if it is read skeptically.
At a 250 m grid, the local Moran map suggests a concentrated set of report hotspots. But the sensitivity table shows how unstable that picture is across spatial resolutions:
- raw-report hotspot cells: 27 at 150 m, 13 at 250 m, 10 at 400 m, 6 at 600 m
- unique-location hotspot cells: 26 at 150 m, 12 at 250 m, 10 at 400 m, 3 at 600 m
That is not a stable hotspot footprint in the strong sense. It is a scale-dependent descriptive pattern. The map is still worth showing because it helps readers see how a municipal archive can generate visually compelling clusters. But the right interpretation is: here is one way the report concentration looks under one aggregation choice, not here is the true set of coyote hotspots.
This is also where the western-side story has to be handled carefully. Some maps do place more visual emphasis on Belmont's west side near Rock Meadow and other greener edge areas. But the same outputs also show central activity, and the hotspot footprint moves around with cell size. So the west-side read is a clue, not a settled result.
Habitat story or reporting story?
The first-pass habitat diagnostics are weaker than the maps make you want them to be.
When unique sighting locations are compared to uniform random points inside Belmont:
- median distance to open space is 138 m for sightings versus 99 m for controls
- median distance to wetlands is 277 m for sightings versus 251 m for controls
- the wetland comparison is weak statistically
- the open-space comparison actually runs against the simple idea that the reports cluster right next to mapped open space
That does not prove the western-edge story is wrong. It does mean the first-pass official layers do not strongly validate it.
There are two reasons to be cautious here.
First, the controls are weak. Uniform random points over Belmont are not a realistic model of where people encounter and report coyotes. An exposure-aware design would sample from places people plausibly observe from: residential parcels, address points, road frontage, or some other human-accessible background.
Second, "open space" is not the same thing as "coyote corridor." Coyotes may move along edges, backyards, informal green strips, cemeteries, rail-adjacent spaces, or other features that this first-pass context set does not capture well.
So the habitat-versus-reporting verdict is asymmetric:
- the reporting-bias evidence is concrete and fairly strong
- the habitat evidence is plausible visually but weak in the first-pass formal tests
What can we say about the super-caller hypothesis?
Not as much as a dramatic version of the story would like.
The public data do not identify reporters. So this analysis cannot prove that one household or one especially dedicated resident generated a large share of the archive. It also cannot prove that repeated addresses correspond to the same person over time.
What it can say is narrower and still important:
- repeated exact points matter
- repeated addresses matter
- repeated address-week combinations exist
- clustering weakens when repeated exact points are collapsed
That is evidence consistent with observer concentration. It is not evidence of a single dominant named reporter.
The safest phrasing is that Belmont's raw map looks more like a mixture of:
- a non-uniform reporting process
- repeat observations from recurring origins
- and possibly some underlying spatial structure in coyote encounters
with the current design unable to separate those cleanly.
A compact methods note for people who want the implementation details
The full workflow is in the exploration outputs, but the high-level implementation choices were:
- the public PeopleGIS query was scripted and saved as a raw JSON artifact
- point geometry was recovered and transformed into Massachusetts mainland meters for spatial analysis
- randomized procedures were seeded with
set.seed(20260408) for reproducibility - all main outputs were regenerated from a single R script
- robustness work compared raw reports, unique exact locations, and a top-repeat-removed variant
- time concentration was summarized separately because the archive spans more than twenty years
- hotspot sensitivity was tabulated across multiple grid sizes instead of relying on one map
If I were taking this into a second, stronger round, the next methodological upgrades would be:
- build an exposure-aware background model
- validate a few point locations directly against known addresses or landmarks as a stronger CRS audit
- stratify or model the archive by time period instead of leaning so heavily on a pooled 2003-2025 surface
- add richer context layers such as rail corridors, cemeteries, parcels, and street network structure
Side quest: weird Massachusetts municipal GIS
This project also turned up a sidecar catalog of other Massachusetts municipal GIS layers that deserve future attention. A few especially promising examples:
- Weston wildlife-reporting infrastructure
- Dedham's tree inventory and sewer infrastructure layers
- Cambridge's street-tree data
Those datasets are not the main event here, but they are a reminder that town GIS portals sometimes contain surprisingly rich raw material for small-scale empirical work.
Limitations
This entire analysis is built on opportunistic public reports rather than a controlled survey or animal-tracking data. The records are pooled across more than two decades. Reporter IDs and narrative notes are absent. The ecological controls are not exposure-aware. KDE and hotspot maps are descriptive and scale-sensitive. The geometry required CRS validation because the viewer metadata could not simply be trusted. And the context layers used here are first-pass rather than exhaustive.
Those are real limitations, but they are not fatal. They just determine what kind of claim this post is allowed to make.
The takeaway
Belmont's public coyote reports are clearly non-uniform, but that is not the same thing as a clean behavioral map of coyotes. The strongest evidence in this package is evidence about reporting concentration: repeated coordinates, repeated addresses, temporal bunching, and clustering that softens after deduplication. The habitat story remains possible, especially in a broad western-edge sense, but the first-pass formal context tests do not carry that story very far.
If you want the disciplined interpretation, it is this: Belmont's coyote map is informative, but mostly as a map of reported encounters shaped by both animal movement and human observation. The raw clusters are real as features of the archive. They are not clean proof of where coyotes "really are."
If you want the replication materials, code, intermediate outputs, and notes, they live here: analysis folder for this project. The main executable pipeline, including the public-data recovery step, is src/run_analysis.R.